
Hace un tiempo llegó un programa que analiza la duplicidad de los documentos y archivos que hay en el computador, la verdad ha sido asombrosa la potencia de este programa, su nombre es ‘fdupes’
Partamos por el principio, el programa se instala de forma normal (para derivados de Debian)
sudo apt install fdupes
Al revisar el manual encontramos:
fdupes – finds duplicate files in a given set of directories
SYNOPSIS
fdupes [ options ] DIRECTORY …DESCRIPTION
Searches the given path for duplicate files. Such files are found by
comparing file sizes and MD5 signatures, followed by a byte-by-byte
comparison.OPTIONS
-r –recurse
for every directory given follow subdirectories encountered
within
El Resultado es impreso en la terminal, lo cual lo hace poco practico, pero como en el mundo gnu/linux es tan hermoso, podemos hacer que imprima donde queramos, por ejemplo un archivo de texto. El siguiente código es el comando básico que más utilizo, el cual entrega el resultado en el archivo ‘duplicados.txt’
fdupes -r . > duplicados.txt
Teniendo un resultado como sale en la imagen siguiente, es decir, agrupando los nombres de los archivos según el parecido.
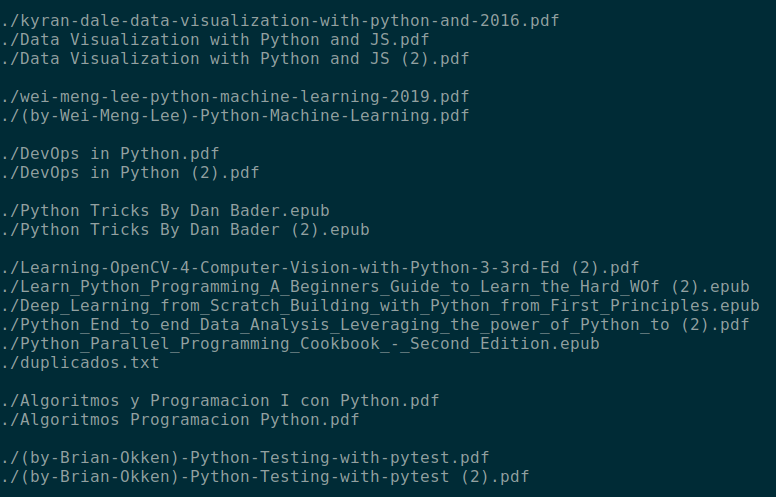
Si se fijan, el resultado puede salir con o sin espacios, tal cual es el nombre, lo que incomoda un poco al momento de trabajar, una forma de formatear los archivos es utilizando ‘sed’.
sed -i ‘s/\ /\\ /g’ duplicados.txt
Con esto se agrega un ‘\’ antes de cada espacio y se podria utilizar un código en bruto como:
cat duplicados.txt | xargs rm
(ojo que para hacer eso primero se debe borrar de la lista los archivos que se deseen conservar)
Pero en caso de querer mover el archivo, el trabajo ya no era tan fácil, así que preguntando por aquí y por allá llegué a dos buenas respuestas que al unirlas me han facilitado bastante las cosas. Por un lado, un gran personaje, conocido como Felix de la Escuela de técnica y cultura hacker, me recordó que existe una opción ‘-I’ de ‘xargs’ que entrega toda la frase a algun comando, para ciertas acciones no me genera problema, pero en otras, me recuerda que xargs parsea por cada espacio, pero ya se genera un avance, el código queda por el momento así:
cat duplicados.txt | xargs -I{} rm {}
Por otro lado, el amigo Mario Pavel, del grupo de Linux del país hermano República Dominicana, me recomienda otro metodo, por un lado decirle a ‘xargs’ que parsee con cada salto de linea y por otro, decirle a mv que mueva todo de una vez y que no se ejecute por cada linea, lo que genera un trabajo mucho más rápido, quedando el código como:
cat duplicados.txt | xargs -d ‘\n’ mv -t ./borrar/
La verdad es que viene súper bien, pero para poder trabajar de forma más universal con xargs, decidí utilizar el siguiente código, una pequeña mezcla que espero con este post que no se me olvide su utilización:
cat duplicados.txt | xargs -d ‘\n’ -I{} rm {}
Si se dan cuenta en un caso es especifico para mv (fue el culpable de las dudas y el generador de la discordia) por ello prefiero utilizar este ultimo código